From Molecules to Matrices – Inside the EBM Harmonization Workshop

How do you explain the complexities of molecular biology to an audience of physicists, engineers, and materials scientists? That was the goal of PD Dr. rer. nat. Dr. habil. med. Katja Kobow, during the latest Harmonization Workshop titled „From Molecules to Matrices,“ a crash course for the students of the EBM program.
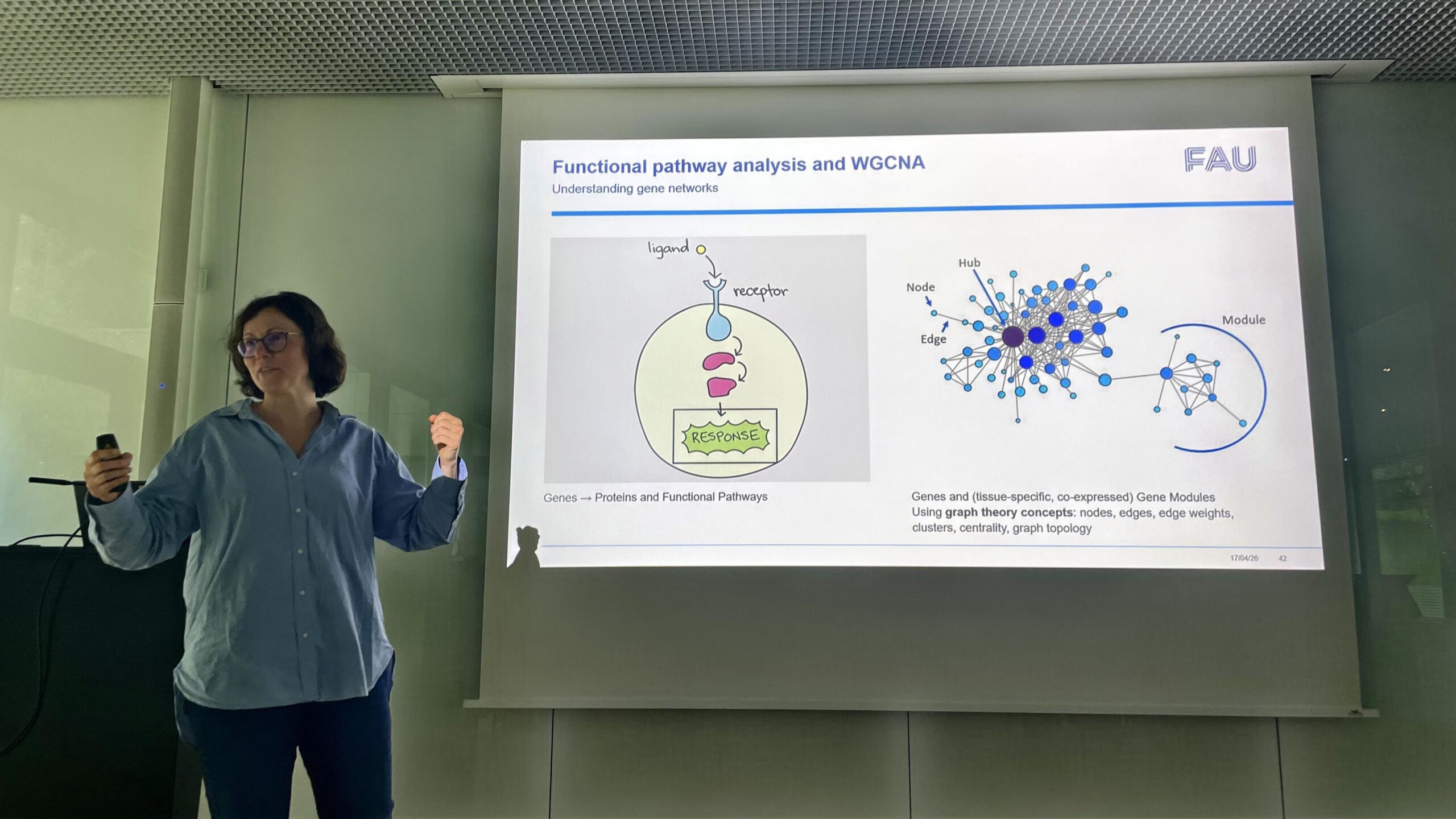
The workshop began by leveling the playing field. Moving swiftly from the central dogma of DNA and mRNA to the latest analytical tools, the session illustrated how the large volume of information generated by molecular biology can be integrated to enable multi-omics analyses. A key takeaway was clear: biology is inherently multi-layered. DNA, RNA, proteins, and epigenetic tags do not act in isolation; they form a deeply interconnected regulatory system. By exploring how these individual molecules scale up into systems (the genome, transcriptome, proteome, and epigenome), the workshop introduced students to the idea of creating a framework for integrating information across all biological layers.
But how do we map these layers onto an organ as intricate as the human brain? As Katja Kobow emphasized, the brain isn’t uniform; its regions vary significantly by local attributes like gene transcription, cytoarchitecture, and temporal dynamics. It comes down to two critical dimensions: space and time. The same somatic mutation along a signalling pathway can cause either a brain tumor or a malformation, depending entirely on where it occurs in the brain.
To capture this spatial and temporal complexity, researchers must make careful methodological choices, because resolution defines what you see. Bulk analysis provides robust averages, single-cell sequencing resolves individual cellular identities, and spatial mapping reveals exact locations—each approach with its own cons. Furthermore, context matters. Cell type, developmental time, age, and other biological confounders determine every single measurement taken.

Transitioning from the biological to the computational, the workshop stressed a crucial rule for data analysis: computational methods only work when the biology is well-framed. In fact, the students learned that most analytical failures are not algorithmic. Instead, they come from poor data hygiene—such as batch effects, hidden confounders, leaky cross-validation, or ignoring multiple testing corrections. To combat this, the message was straightforward: reproducibility requires methodological transparency, controlled pipelines, and rigorous independent validation.

The workshop then looked at the future of data integration with Dr. Paraskevi Chasani, who introduced MOFA (Multi-Omics Factor Analysis) to navigate these exact computational challenges, which provides a robust way to define patterns even when data is missing or incomplete.
As a final highlight before closing, Katja Kobow shared a sneak peek of a personal project she’s been working on. She demonstrated a full, easy-to-use epigenomics analysis pipeline that runs directly in the browser—a tool still in development but soon to be published. Built for students and powered by real data, the app is designed to make complex omics analysis accessible and hands-on.
By the end of the session, the EBM researchers left with more than just notes; they gained a unified vocabulary. From the mechanics of a single molecule to the complexity of a data matrix, the workshop proved that harmonizing diverse backgrounds is the first step toward decoding the brain.
Erica Cecchini, A02